Something I've thought about for at least a decade (damn, more like two...) is addressing the compute-memory bottleneck (be that RAM memory, storage, etc.) by integrating processing power into the memory itself. This memory-first approach is rare in the design of most computer systems (even within the realm of contemporary high-performance computing) and I've long thought it has the potential to unleash an orders-of-magnitude increase in throughput for systems whose applications require vast amounts of data.
The first concrete application of this design occurred to me when actively working on JSFS. While primarily a storage system, I started the JSFS project as part of what could best be described as an operating system effort to backfill the pieces needed to write end-to-end applications in HTML and Javascript. The filesystem alone turned out to be useful and so the more ambitious ideas got set-aside, and since then I've never had an opportunity to pursue the work full-time, but the two things I had planned next were federation and compute.
A few years later I spent a lot of time working with Spark, Hadoop and other big-data-oriented systems and thought about how the ideas I had for adding compute to JSFS (JSFSX) could apply to these problems. One of the things I found most interesting about Spark was the idea of data-locality. By splitting large datasets into "chunks" that could be processed in parallel, and storing these chunks close or local to where they're processed overall processing times can be reduced. However things like Spark tend to work with big grains (both in terms of data and processing nodes) and so a typical Spark job needs to be very large before the speedup pays-back the overhead cost of splitting up the job, moving data to nodes, bringing it back together, etc.
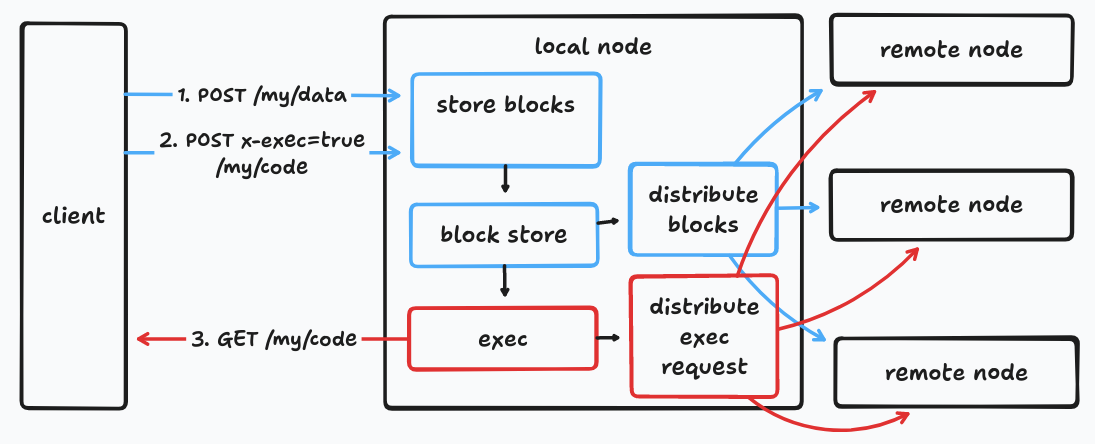
A very high-level sketch of JSFS + Federation & Execute
The JSFSX approach works with much smaller grains, ideally a single block (1MB by default in JSFS) which makes this approach suitable for smaller workloads. This not only makes it useful for smaller overall jobs but also makes it easier to partition big jobs (instead of having to jump through hoops to "lump" things together to fit into the Spark/Hadoop model). Smaller grains are also more suitable for thread-level parallelism which makes the most out of manycore CPU's. For jobs too big for a single node JSFS federation can be used to scale-out across multiple nodes. The federation designs I was working with distribute data automatically across federated nodes, so there's no need for a "setup" step to
scatter" the data "grains" out across the cluster and no need to "gather" them at the end; instead it is the instructions that are sent-out across the cluster at runtime which should be much smaller than the data being processed.
This was, to me, the most rudimentary way to accomplish the sort of "memory+processing" architecture while still providing practical application value and utilizing technology that is within my reach. It also provides a place to experiment with various application development patterns and to fine-tune the federation, multiprocessing schedule and other algorithms.
The next step is to push this model down the stack, first to a unikernel, then to an FPGA and finally to truly custom silicon: memories with integrated compute cores. I thought that the first two would be possible if I could find a way to work on the project full-time but I never imagined that I'd be able to take it all the way down to the final step. I've since learned more about the hardware layers and I'm at a point where I feel confident that I could take it all the way down to the silicon; at least to the design stage and potentially beyond.
The reason I bring this all up is that it's ten years later and I'm starting to see discussion of this problem bubbling-up to the surface of mainstream tech sector discussion. When I first started working on these ideas I had a very hard time explaining the necessity of them to others, but perhaps now it might be easier to communicate the value of this approach.
![]()