This project is about building a big computer to provide all of the services needed to run Kratz-Gullickson Laboratories on-premise, without an Internet connection.
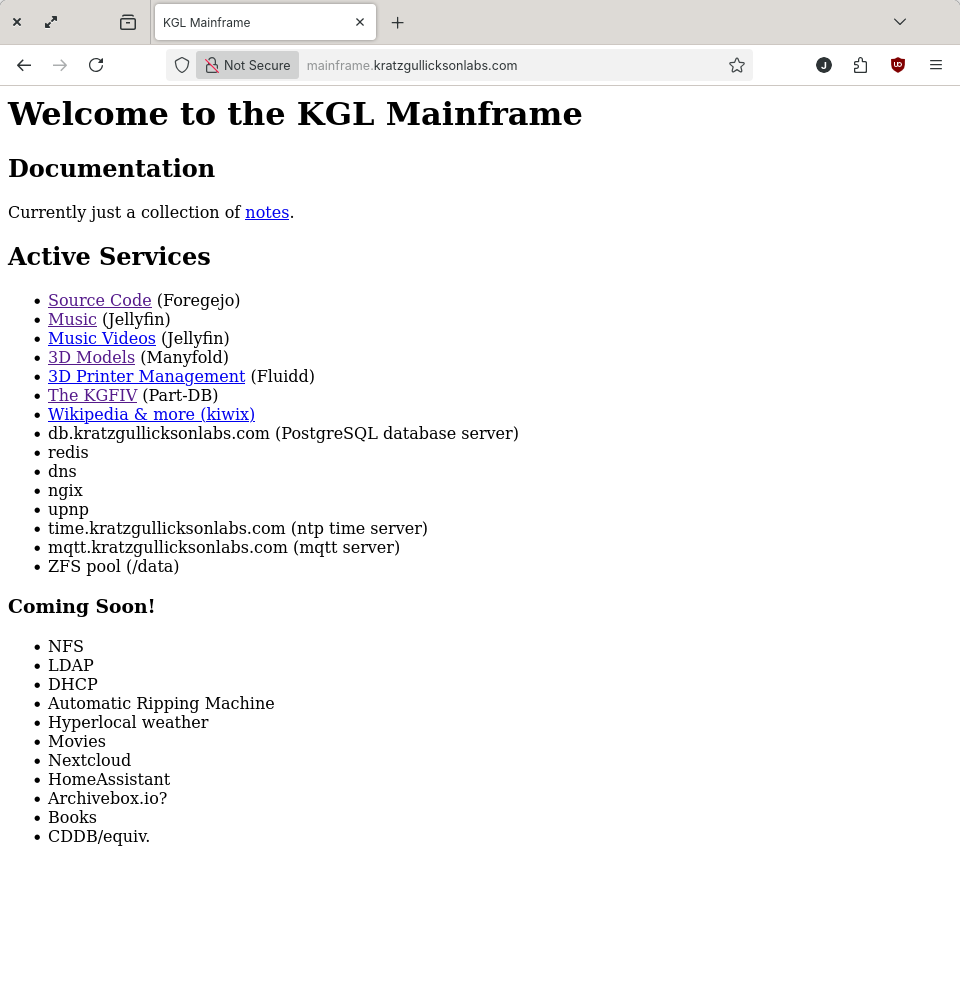
I've wanted to do this for a while but kept waiting to have the ideal hardware configuration before getting started. I decided about a week or so ago to stop waiting, and build the mainframe out of whatever I had on-hand. Over time, the hardware will evolve (ideally into a digital bug-out box of some sort) but I can figure out a lot of the software side of things in the meantime.
Current hardware consists of 4 DL360-based processors and a Backblaze Storage Pod-based storage system. At the moment all services are running on the storage system as I bring each of the processors online (the delay has more to do with power supply than anything else). This seems kind of dumb but remember I don't want to wait any longer, and doing it this way gives me a chance to test migrating services around while the stakes are low.
The design philosophy behind the system is to use "native" software whenever possible (as opposed to containers, etc.) There is a focus on creating strong, resilient stand-alone services for networking, storage, database, etc. and having applications consume these core services as shared resources instead of running multiple copies of everything inside some multilayered abstraction. This is preferred for performance of course, but also because I really want to know how to make all these things work so I can fix them when they don't.
That said, there are currently some exceptions to this for some applications due to limited documentation (limited documentation outside of "just use Docker") or unusual dependencies that I need to learn more about before I'm ready to commit to implementing them as shared services. Again, I expect this to improve over time.
I'll summarize the services the mainframe provides in this post for now. I'll write some follow-up posts to talk about some of the more complex to setup/operate/use services in future posts.
Applications
Source Code Repository (Forgejo)
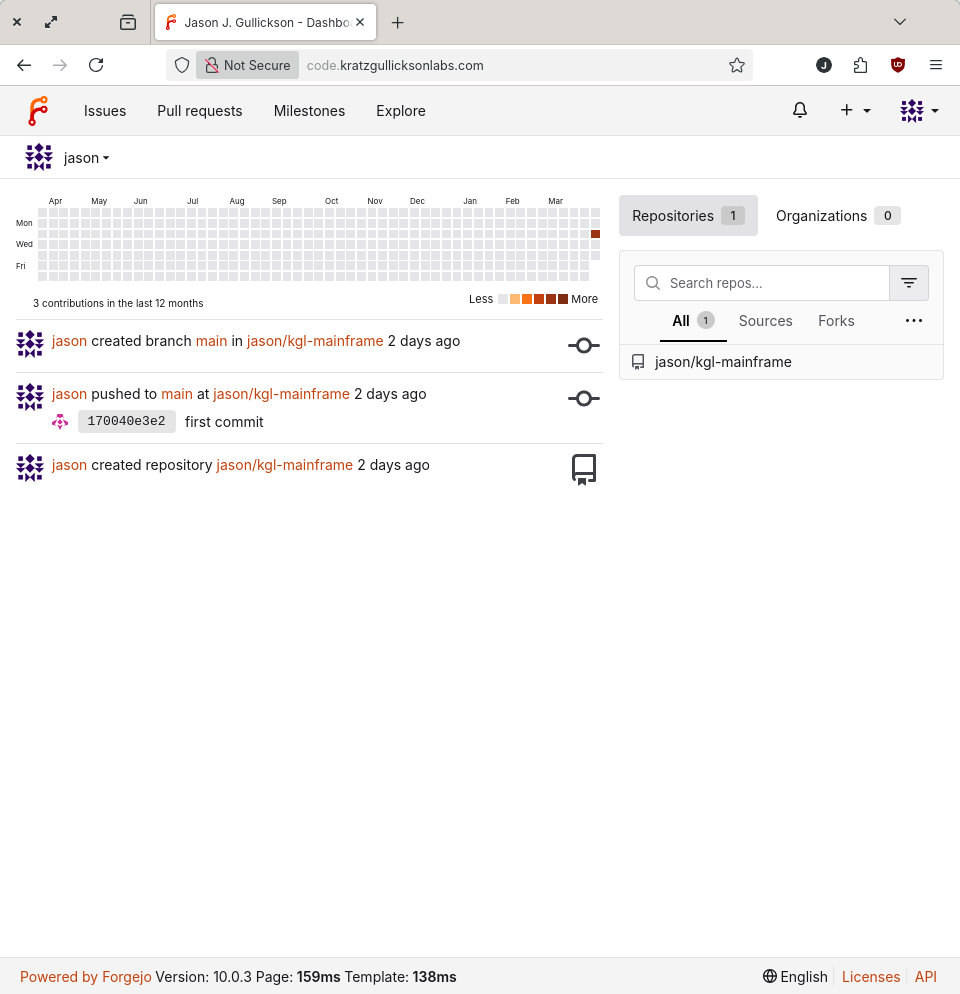
Forgejo is the software that powers Codeberg, and aside from being a great alternative to Github, it's fast, light and will eventually support federation. Installing Forgejo was straightforward (I'll detail it in a future post) and I'm looking forward to making it the origin repo for all projects.
Music Streaming (Jellyfin)
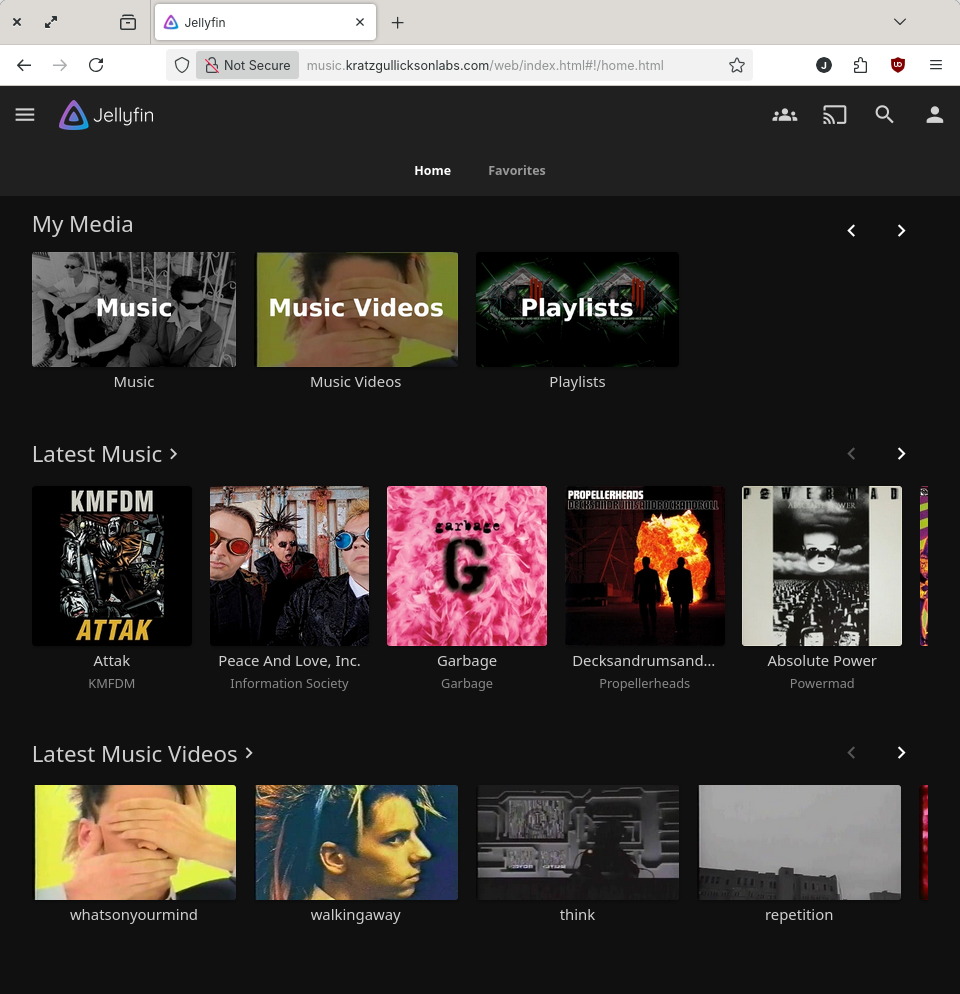
Pete suggested Jellyfin as an alternative to PLEX and so far it's been working great. I originally configured it for our music library (~500 CD's at the moment) because I didn't have enough storage online to store much video, but I'll be adding movies and shows soon now that I've expanded the storage array.
3D Model Database (Manyfold)
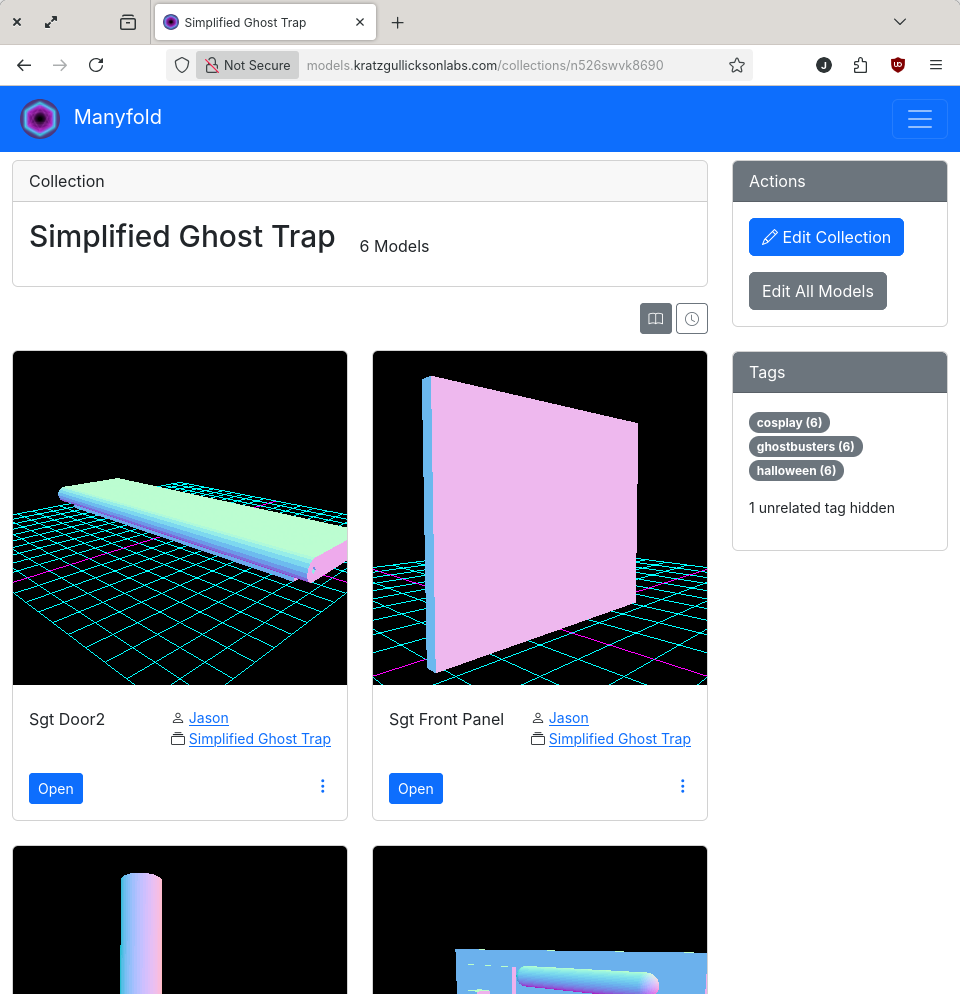
This is something we've needed in the lab for a long time, as relying on similar services provided by 3D printer manufacturers (Thingiverse, Printables, etc.) has been a problem in the past and it's easy to see how the pattern will repeat. I haven't spent a lot of time using Manyfold, and so far I've tripped over a few limitations, but I'm hopeful that it can be made to work well, and I'm particularly excited about it's support for federation so we can share model libraries with other sites.
3D Printer Control (Fluidd)
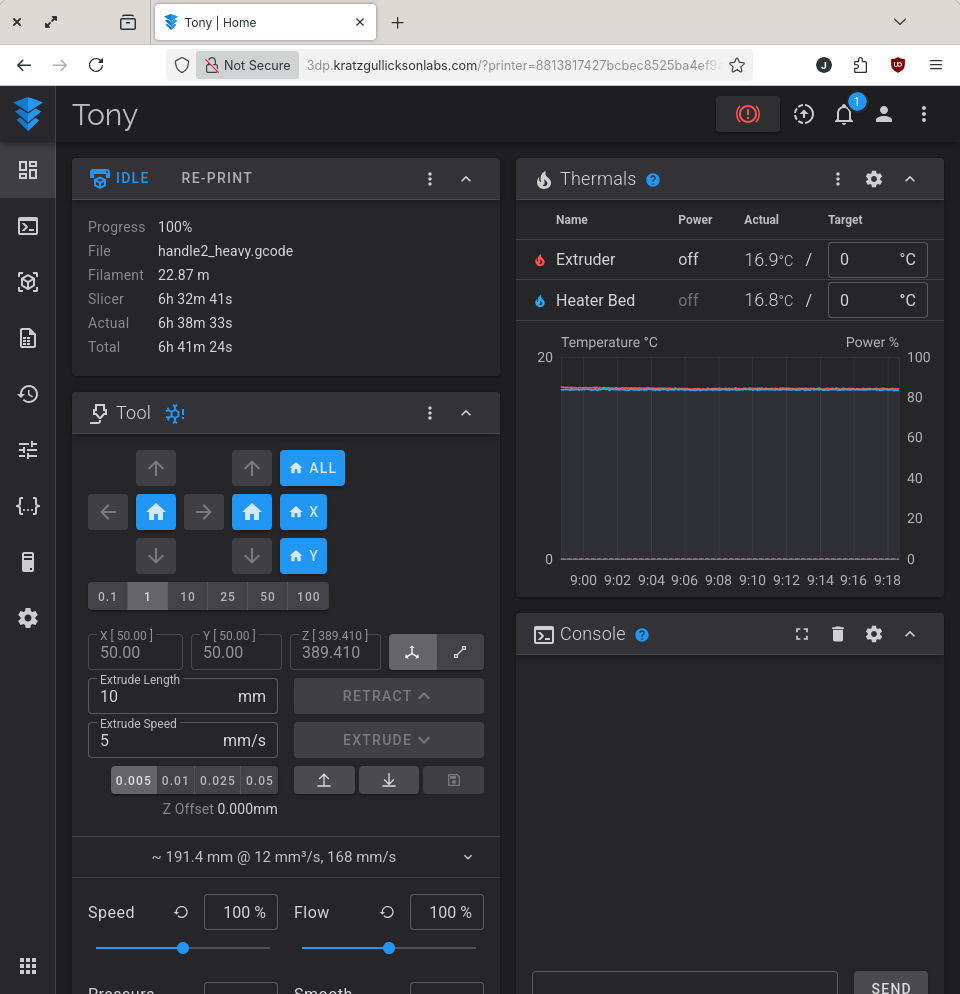
I've recently been introduced to Klipper and the Fluidd UI through the aquisition of an Orangestorm Giga, and since then I've started converting my other printers to use the same setup. One of the nice features of the Fluidd UI is that it can connect to multiple printers. I don't want to burden any of the little machines responsible for driving the printers with this task so I've deployed a Fluidd server as a service on the mainframe. I've only begun to work with this, and there are some hang-ups around CORS, etc. to getting it working, but with some work I think it's going to be very handy.
The KGFIV (Part-DB)
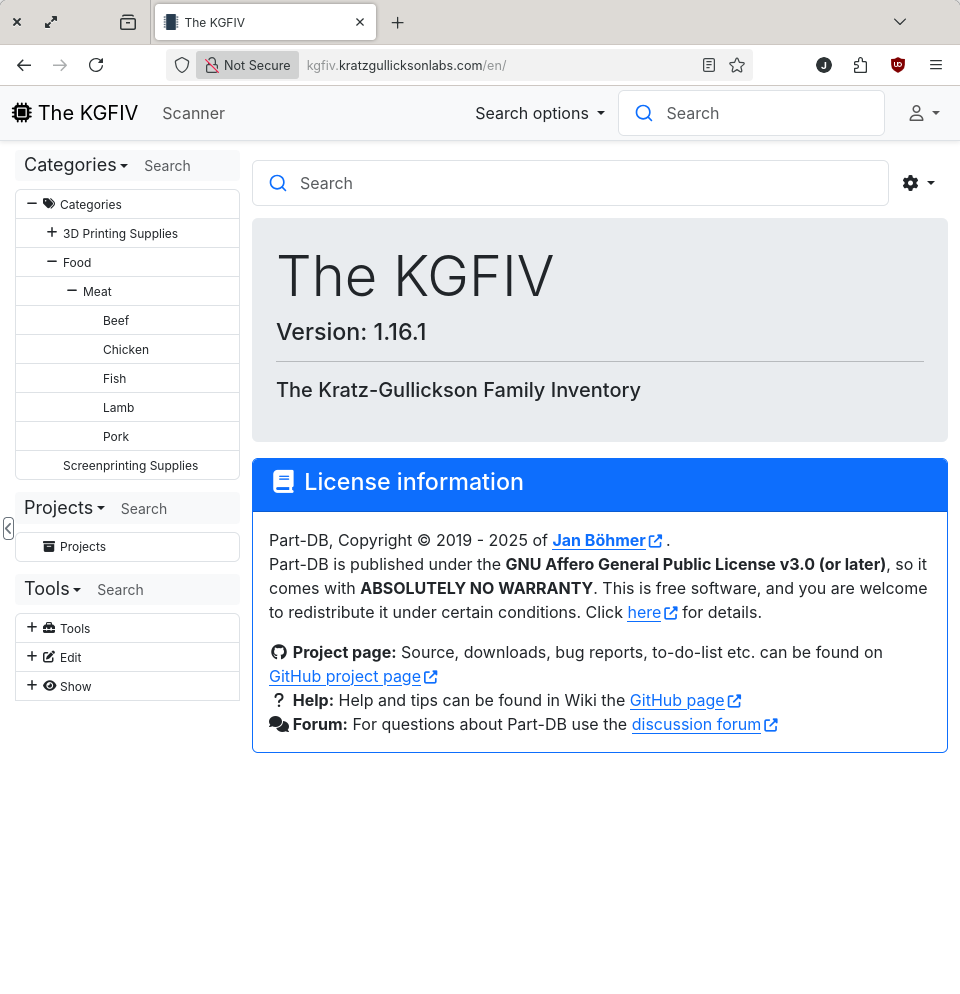
Part-DB is designed for maintaining an inventory of electronic components, but it's flexible enough to do inventory for just about anything (I'm currently using it to keep track of what's in the deep freeze). I've only scratched the surface of what this software is capable of, and really putting it to work is going to be a major inventory undertaking, but in the long-run it's going to save a lot of time and money when we're able to know what parts we have, what parts we need to buy and where exactly to find them.
Wikipedia (Kiwix)
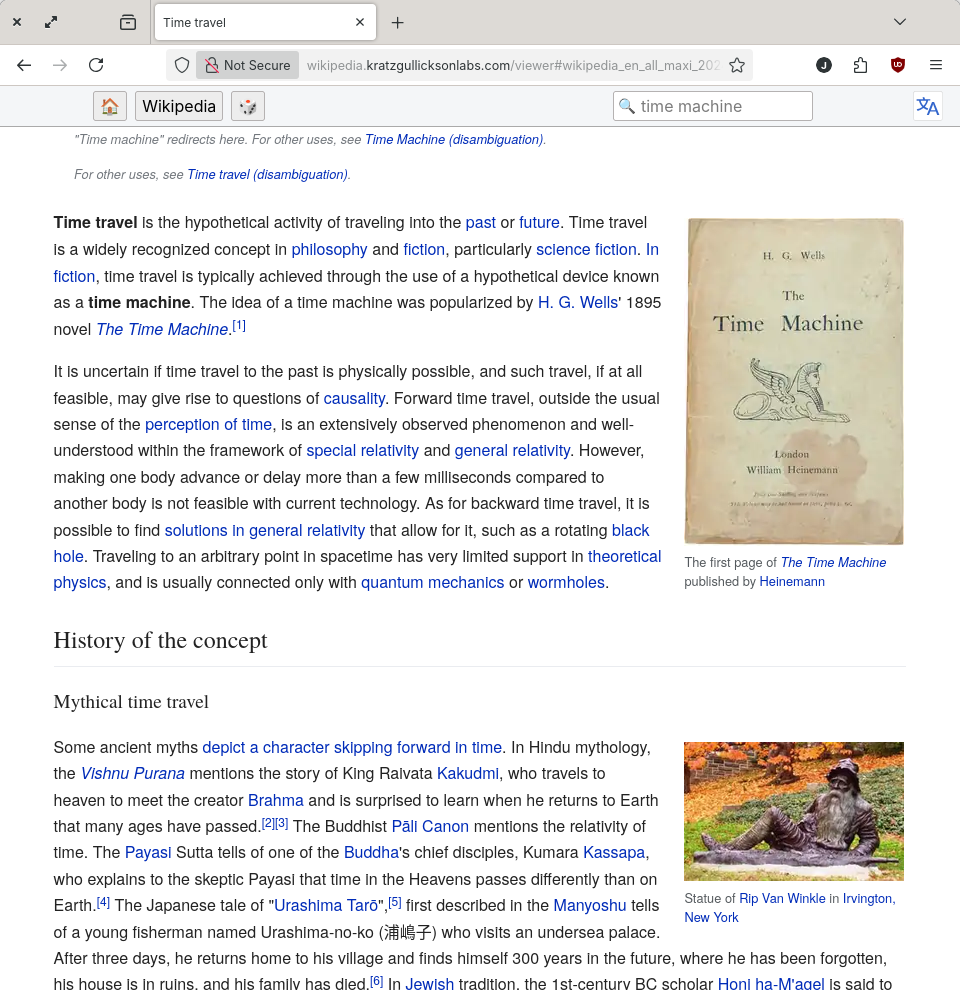
I've wanted an "offline" copy of Wikipedia for decades, and I even experimented with running a full-blown replica. Now it's much simpler by using software and data provided by Kiwix which is simple to setup & run. In addition to Wikipedia, Kiwix packages lots of other useful and interesting datasets that I'll be adding to our library over time.
Services
The rest of these services require no introduction. They provide the core infrastructure used by the applications detailed above.
* RDBMS (PostgreSQL)
* KV Store (Redis)
* DNS (BIND)
* Web Server (NGINX)
* Network Time (NTP)
* MQTT Broker (Mosquitto)
* Mass Storage (OpenZFS)
What's Next?
As I build-out the system and become reliant on it, the list of additional services grows. Here's what I've got planned for the near future:
* Network Filesystem (NFS)
* Directory Services (LDAP)
* DHCP
* Hyperlocal Weather
* Automatic media ingestion
* Movie Streaming
* Home Automation (HomeAssistant)
* CDDB